En av suksessene med ΛCDM-modellen for universet er muligheten for modeller til å lage strukturer med skalaer og fordelinger som ligner de vi ser i Space Magazine. Mens datasimuleringer kan gjenskape numeriske universer i en boks, er det å tolke disse matematiske tilnærminger en utfordring i og for seg selv. For å identifisere komponentene i det simulerte rommet, har astronomer måttet utvikle verktøy for å søke etter struktur. Resultatene har vært nesten 30 uavhengige dataprogrammer siden 1974. Hver av dem lover å avsløre den dannende strukturen i universet ved å finne regioner der mørke materie-haloer dannes. For å teste disse algoritmene ble det arrangert en konferanse i Madrid, Spania i løpet av mai 2010 med tittelen “Haloes going MAD” hvor 18 av disse kodene ble satt på prøve for å se hvor godt de stablet opp.
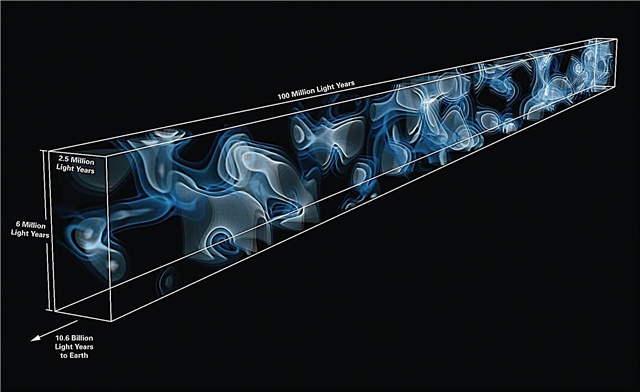
Numeriske simuleringer for universer, som den berømte tusenårsimuleringen, begynner med ikke annet enn "partikler". Selv om disse utvilsomt var små i kosmologisk skala, representerer slike partikler klatter av mørk materie med millioner eller milliarder solmasser. Når tiden kjøres fremover, får de lov til å samhandle med hverandre etter regler som sammenfaller med vår beste forståelse av fysikk og arten av slik materie. Dette fører til et univers i utvikling som astronomer må bruke de kompliserte kodene for å lokalisere konglomerasjonene av mørk materie som galakser ville danne seg i.
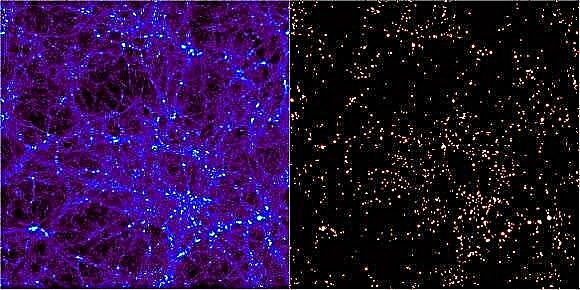
En av de viktigste metodene slike programmer bruker er å søke etter små overdensiteter og deretter vokse et sfærisk skall rundt det til tettheten faller til en ubetydelig faktor. De fleste vil deretter beskjære partiklene innenfor volumet som ikke er gravitasjonsmessig bundet for å sørge for at deteksjonsmekanismen ikke bare benyttet seg av en kort, kortvarig klynge som vil falle fra hverandre i tid. Andre teknikker innebærer å søke i andre faserom etter partikler med lignende hastigheter alle i nærheten (et tegn på at de har blitt bundet).
For å sammenligne hvordan hver av algoritmene gikk, ble de satt gjennom to tester. Den første involverte en serie med vilje skapt mørke materie-haloer med innebygde under-haloer. Siden partikkeldistribusjonen med vilje ble plassert, skulle output fra programmene finne sentrum og størrelse på glorieene riktig. Den andre testen var en fullverdig universalsimulering. I dette vil den faktiske distribusjonen ikke være kjent, men den store størrelsen vil tillate å sammenligne forskjellige programmer på det samme datasettet for å se hvor lignende de tolket en vanlig kilde.
I begge testene presterte generelt alle søkerne bra. I den første testen var det noen avvik basert på hvordan forskjellige programmer definerte plasseringen av haloer. Noen definerte den som toppen i tetthet, mens andre definerte den som et massesenter. Når de søkte etter sub-haloer, syntes de som brukte fase-romtilnærmingen å være i stand til mer pålitelig å oppdage mindre formasjoner, men oppdaget ikke alltid hvilke partikler i klumpen som faktisk var bundet. For full simulering var alle algoritmer eksepsjonelt godt enige. På grunn av simuleringens natur var små skalaer ikke godt representert, så forståelsen av hvordan hver oppdager disse strukturene var begrenset.
Kombinasjonen av disse testene favoriserte ikke en bestemt algoritme eller metode fremfor noen annen. Det avslørte at hver generelt fungerer bra med hensyn til hverandre. Evnen til så mange uavhengige koder, med uavhengige metoder, betyr at funnene er ekstremt robuste. Kunnskapen de viderefører om hvordan vår forståelse av universet utvikler seg, gjør at astronomer kan gjøre grunnleggende sammenligninger med det observerbare universet for å teste slike modeller og teorier.
Resultatene av denne testen er samlet i et papir som er beregnet for publisering i en kommende utgave av Monthly Notices of the Royal Astronomical Society.